It is always interesting to hear from Jeff and understand what he is upto. I have blogged about his earlier talks at XLDB and at Stanford. Jeff Dean’s Keynote at RecSys2014 was no exception. The talk was interesting, the Q&A was stimulating and the links to papers … now we have more work ! – I have a reading list at the end.
Of course, you should watch it (YouTube Link) and go thru his keynote slides at the ACM Conference on Information and Knowledge Managment. Highlights of his talk, from my notes …

- Build a system with simple algorithms and then throw lots of data – let the system build the abstractions. Interesting line of thought;
- I remember hearing about it from Peter Norwig as well ie Google is interested in algorithms that get better with data
- An effective recommendation system requires context ie. understand the user’s surroundings, previous behavior of the user, previous aggregated behavior of many other users and finally textual understanding.

-
He then elaborated one of the area they are working on — semantic embeddings, paragraph vector and similar mechanisms

Interesting concept of embedding similar things such that they are nearby in a high dimensional space!
- Jeff then talked about using LSTM (Long Short-Term Memory) Neural Networks for translation.

- Notes from Q & A:
- The async training of the model and random initialization means that different runs will result in different models; but results are within epsilon
- Currently, they are handcrafting the topology of these networks ie now many layers, how many nodes, the connections et al. Evolving the architecture (for example adding a neuron when an interesting feature is discovered) is still a research topic.
- Between ages of 2 & 4, our brain creates 500K neurons / sec and from 5 to 15, starts pruning them !
- The models are opaque and do not have explainability. One way Google is approaching this is by building tools that introspect the models … interesting
- These models work well for classification as well as ranking. (Note : I should try this – may be for a Kaggle competition. 2015 RecSys Challenge !)
- Training CTR system on a nightly basis ?
- Connections & Scale of the models
- Vision : Billions of connections
- Language embeddings : 1000s of millions of connections
- If one has more data, one should have less parameters;otherwise it will overfit
- Rule of thumb : For sparse representations, one parameter per record
- Paragraph vector can capture granular levels while a deep lSTM might be better in capturing the details – TBD
- Debugging is still an art. Check the modelling; factor into smaller problems; see if different data is required
- RBMs and energy based models have not found their way into GOOGL’s production; NNs are finding applications
- Simplification & Complexity : NNs, once you get them working, forms this nice “Algoritmically simple computation mechanisms” in a darkish-brown box ! Less sub systems, less human engineering ! At a different axis of complexity
- Embedding editorial policies is not easy, better to overlay them … [Note : We have an architecture where the pre and post processors annotate the recommendations/results from a DL system]
- There are some interesting papers on both the topics that Jeff mentioned (This my reading list for the next few months! Hope it is useful to you as well !):
- Efficient Estimation of Word Representations in Vector Space [Link]
- Paragraph vector : Distributed Representations of Sentences and Documents [Link]
- [Quoc V.lee ‘s home page]
- Distributed Representations of Words and Phrases and their Compositionality [Link]
- Deep Visual-Semantic Embedding Model [Link]
- Sequence to Sequence Learning with Neural Networks [Link]
- Building high-level features using large scale unsupervised learning [Link]
- word2vec Tool for computing continuous distribution of words [Link]
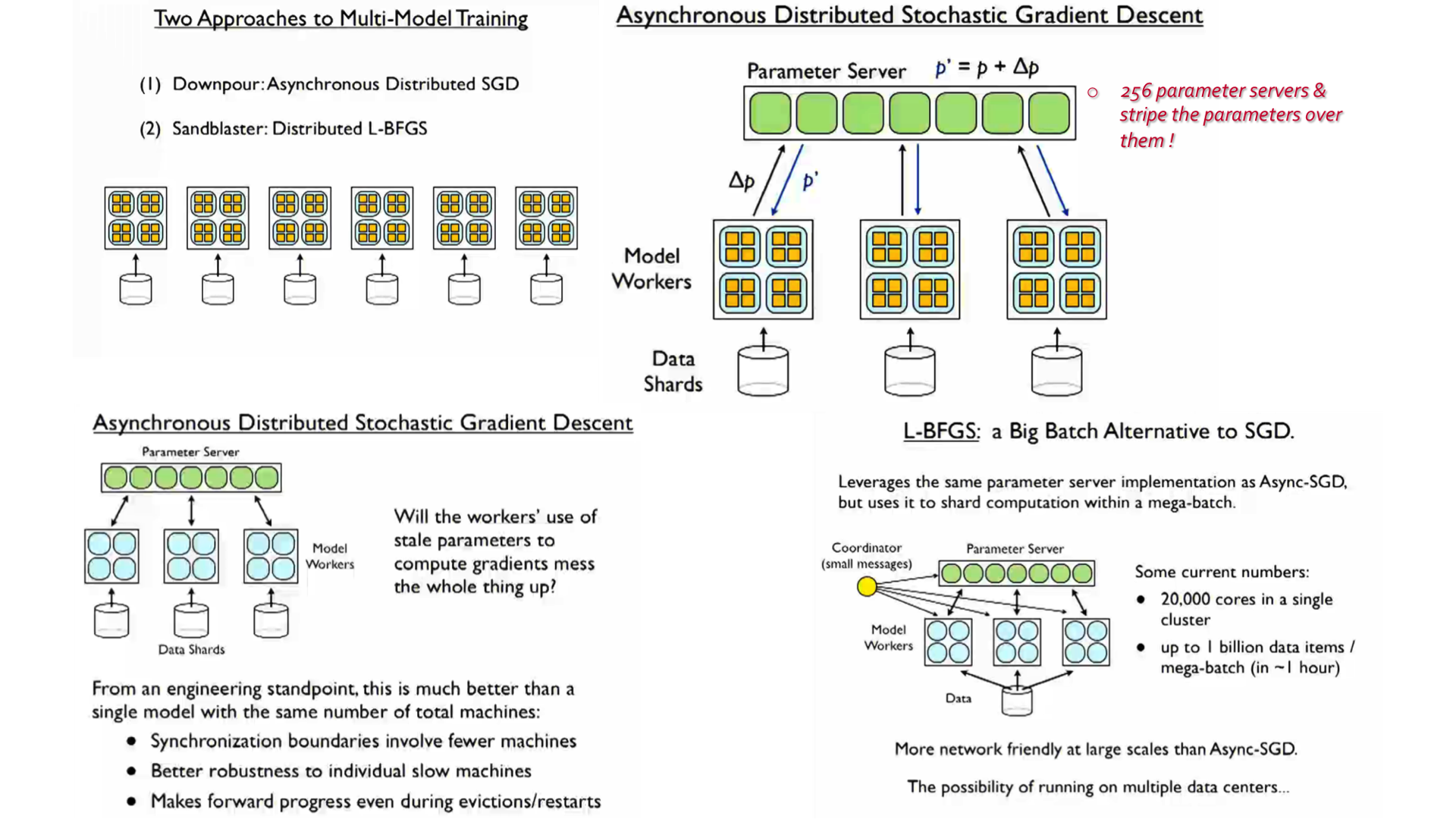
- Large Scale Distributed Deep Networks [Link]
- Deep Neural Networks for Object Detection [Link]
- Playing Atari with Deep Reinforcement Learning [Link]
- Papers by Google’s Deep Learning Team [Link to Vincent Vanhoucke’s Page]
- And, last but not least, Jeff Dean’s Page
The talk was cut off after ~45 minutes. Am hoping they would publish the rest and the slides. Will add pointers when they are on-line. Drop me a note if you catch them …
Update [10/12/14 21:49] : They have posted the second half ! An watching it now !
Context : I couldn’t attend the RecSys 2014; luckily they have the sessions on YouTube. Plan to watch, take notes & blog the highlights; Recommendation Systems are one of my interest areas.
- Next : Netflix’s CPO Neal Hunt’s Keynote
- Next + 1 : Future Of recommender Systems
- Next + 2 : Interesting Notes from rest of the sessions
- Oh man, I really missed the RecSysTV session. We are working on some addressable recommendations. Already reading the papers. Didn’t see the video for the RecSysTV sessions ;o(